
Has leído bien, en el artículo de hoy aprenderemos a calcular tamaño del modelo semántico usando Semantic Link y es que desde la versión 0.6 han aparecido nuevos métodos list* que nos van a permitir hacerlo, y no sobre un único modelo semántico, sino todos los modelos de un área de trabajo. Esto lo conseguiremos gracias a un Notebook de Fabric.
Requisitos previos
Antes de continuar comprueba que tienes configurados los siguientes requisitos previos:
- Tener instalada la librería semantic-link (en su versión 0.6 como mínimo)
Preparando el Notebook
Crea un nuevo Notebook en tu área de trabajo y escoge el entorno que tenga configurada la Liberia semantic-link

Alernativa
Si no quieres crear un entorno con la librería tu primera línea de código debe ser la siguiente para instalar la librería: %pip install semantic-link --q
Código de ejemplo
Crea un bloque e importa Fabric Semantic Link, pandas y datetime.
import sempy.fabric as fabric import pandas as pd import datetime
En un nuevo bloque escribe el siguiente código para conseguir listar todos los modelos semánticos de Power BI de las capacidades activas y de las áreas de trabajo Premium o de tipo Fabric.
def analizar_espacio_modelo(eliminar_modelos_semanticos_defecto=True):
def obtenerTamañoModeloSemantico(workspace, dataset):
columnas = fabric.list_columns(workspace=workspace, dataset=dataset, extended=True)
espacio = sum(columnas["Total Size"])
columnasCalculadas = sum(columnas[columnas.Type == "Calculated"]["Total Size"])
tablasCalculadas = sum(columnas.query('Type == "CalculatedTableColumn"')["Total Size"])
fechasAutomaticas = sum(columnas[columnas['Table Name'].str.startswith(("DateTableTemplate_", "LocalDateTable_"))]["Total Size"])
columnasDecimales = sum(columnas.query('`Data Type` == "Double"')["Total Size"])
espacio_jerarquias = sum(columnas["Hierarchy Size"])
num_tablas = columnas["Table Name"].nunique()
return espacio, columnasCalculadas, tablasCalculadas, fechasAutomaticas, columnasDecimales, espacio_jerarquias, num_tablas
#Obtener solo las capacidades activas
capacidades_activas = fabric.list_capacities().query('State == "Active"')
#Areas de trabajo premium o de fabric
areasCapacidadDedicada = fabric.list_workspaces().query('`Is On Dedicated Capacity`==True')
areasTrabajoPremium = areasCapacidadDedicada[areasCapacidadDedicada['Capacity Id'].isin(list(capacidades_activas.Id))]
modelosSemanticos = pd.concat([fabric.list_datasets(areasCapacidadDedicada).assign(workspace=areasCapacidadDedicada) for areasCapacidadDedicada in areasTrabajoPremium['Name']], ignore_index=True)
listaColumnas = ['total_columnsize_MB', 'pct_size_calculated_cols', 'pct_size_calculated_tables',
'pct_size_autodatetime', 'pct_size_floats', 'pct_hierarchy_size','number_of_tables']
catalogo = modelosSemanticos[["workspace", "Dataset Name"]].copy().assign(Fecha = datetime.date.today())
catalogo[listaColumnas] = pd.NA
for i, row in catalogo.iterrows():
try:
espacio, columnasCalculadas, tablasCalculadas, fechasAutomaticas, columnasDecimales, espacio_jerarquias, num_tablas = obtenerTamañoModeloSemantico(row["workspace"], row["Dataset Name"])
catalogo.loc[i, ['total_columnsize_MB', "pct_size_calculated_cols", 'pct_size_calculated_tables',
'pct_size_autodatetime', 'pct_size_floats', 'pct_hierarchy_size', 'number_of_tables']] = [
round(espacio/(1024**2), 1), round(100 * (columnasCalculadas / espacio), 1), round(100 * (tablasCalculadas / espacio), 1),
round(100 * (fechasAutomaticas / espacio), 1), round(100 * (columnasDecimales / espacio), 1), round(100 * (espacio_jerarquias / espacio), 1), int(num_tablas)
]
#Excpetion to handle default datasets which do not have XMLA endpoint
except Exception:
continue
for columna in listaColumnas:
catalogo[columna]=pd.to_numeric(catalogo[columna], errors='coerce')
if eliminar_modelos_semanticos_defecto:
#Los conjuntos de datos predeterminados mostrarán valores de NaN.
#Para incluir los modelos por defecto, modifica eliminar_modelos_semanticos_defecto=False
catalogo.dropna(inplace=True)
#Ordenar descendentemente por el tamaño total de columnas en MB
catalogo.sort_values(by=['total_columnsize_MB'], ascending=False, inplace=True)
catalogo.reset_index(drop=True, inplace=True)
return catalogo
#Asignamos a dataFrameResultado el resultado de la función
dataFrameResultado = analizar_espacio_modelo()
#Renombramos las columnas de dataFrameResultado y lo mostramos
dataFrameResultado.rename(columns={"workspace": "Área de trabajo", "Dataset Name": "Modelo Semántico" ,"total_columnsize_MB":"Total Tamaño Columnas (MB)",
"pct_size_calculated_cols":"% Tamaño Columnas calculadas","pct_size_calculated_tables":"% Tamaño Tablas calculadas",
"pct_size_autodatetime":"% Tamaño Fechas Automaticas","pct_size_floats":"% Tamaño Columnas Decimales",
"pct_hierarchy_size":"% Tamaño Jerarquías","number_of_tables":"Nº Tablas"})
El resultado debe ser similar al siguiente:
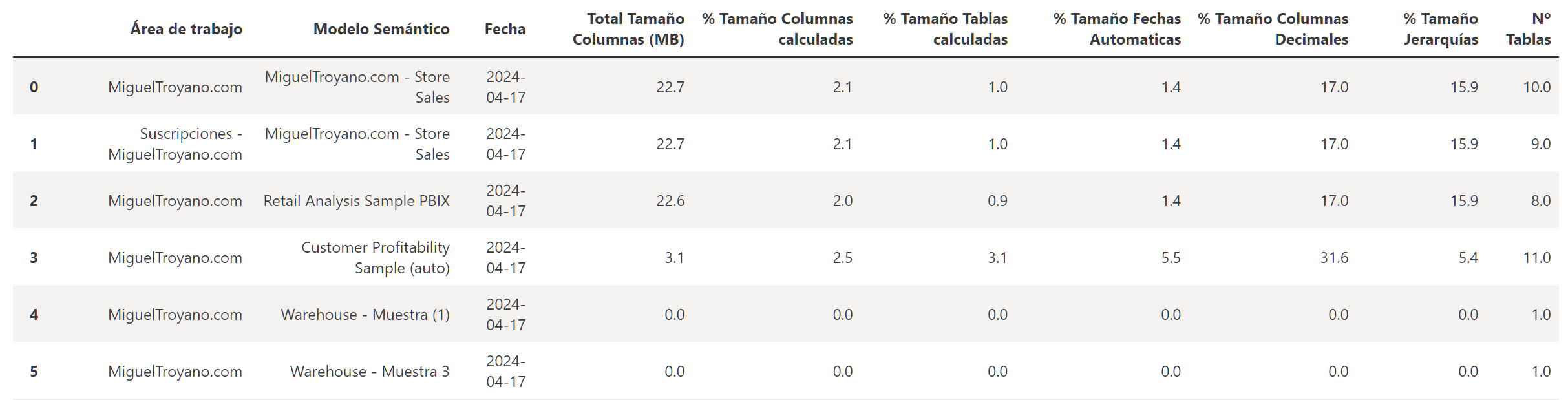
Las columnas que devuelve, de izquierda a derecha son:
- Nombre del área de trabajo.
- Nombre del modelo semántico.
- Fecha de cuando se ha realizado la ejecución.
- Tamaño general del modelo semántico basado en el tamaño de la columna (incluye datos, diccionario y tamaño de jerarquía)
- % del tamaño por columnas calculadas en el modelo.
- % del tamaño según tablas calculadas.
- % del tamaño por fecha y hora automática (ya sabes que las fechas automáticas aumentan el tamaño de los modelos)
- % del tamaño de columnas que tienen tipo de datos decimal.
- % del tamaño por jerarquía de columnas.
- Número de tablas en el modelo
Siguientes pasos
Lo puedes utilizar simplemente como información para mejorar tu modelo, pero tiene otros usos como historificar el tamaño de tu modelo. El resultado de este cuaderno lo puedes almacenar en un Lakehouse de Fabric y planificar su ejecución con las canalizaciones. Tendrás día por día cómo ha ido aumentando tu modelo.
Fuente
El autor original del código es https://fabric.guru/. Este artículo es una transcripción y adaptación al castellano.