
Las consultas en XPath permiten acceder y extraer información específica de un documento XML de manera eficiente. Este lenguaje ofrece una amplia variedad de funciones, como operaciones numéricas, selección de nodos, manejo de posiciones y mucho más. Además, es posible crear consultas anidadas para resolver casos más complejos. ¡Es hora de empezar!
Fichero de ejemplo
Los ejemplos que presentaré a continuación se ejecutarán utilizando la herramienta gratuita BaseX, y para ello emplearé el archivo XML de ejemplo introducido en artículos anteriores. Esta herramienta es ideal para explorar y practicar con consultas en XPath y XQuery de manera sencilla.
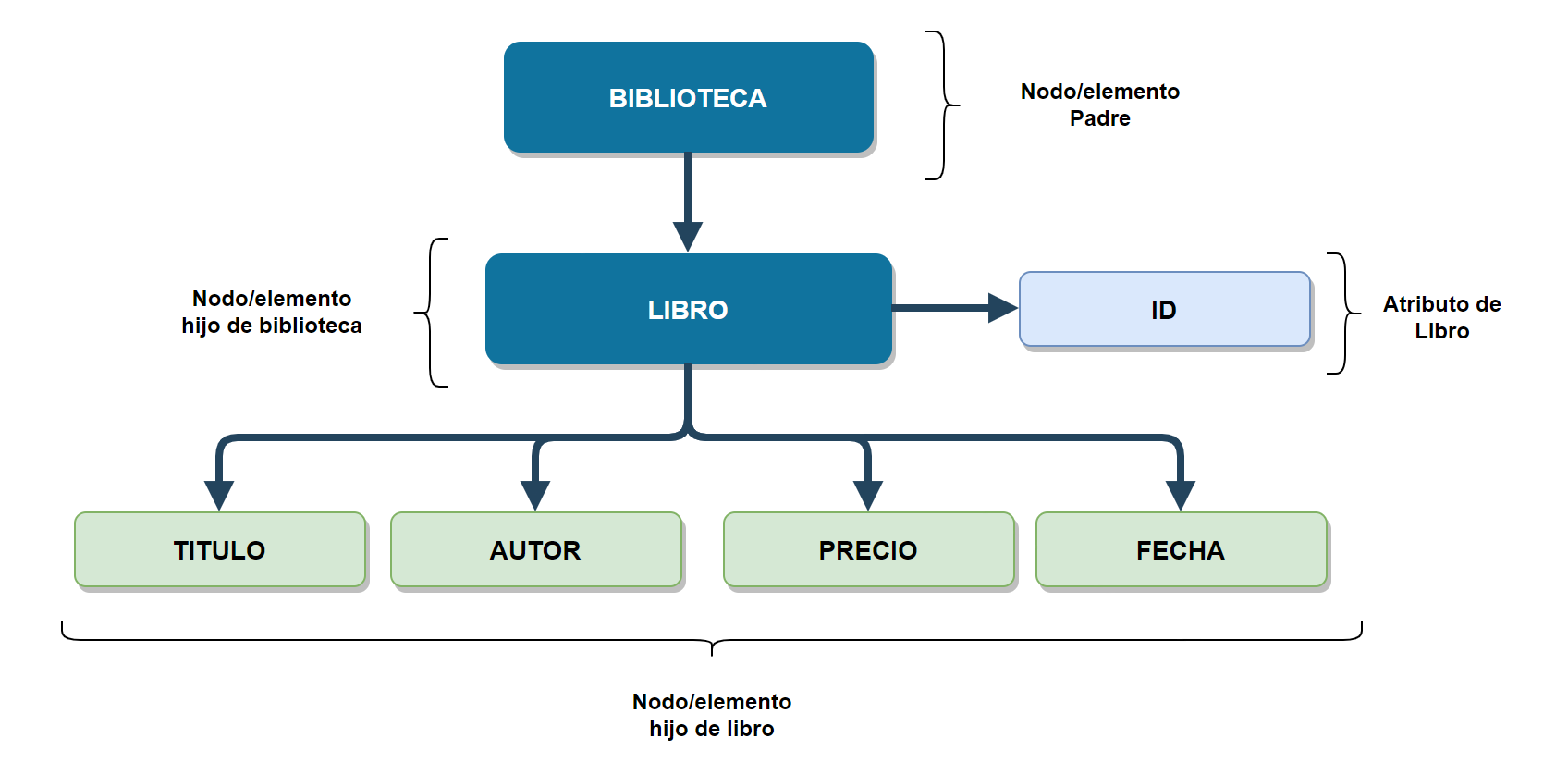
Localización
El direccionamiento, o localización, en un documento XML consiste en definir una ruta de nodos que permita acceder a las partes específicas de su contenido. Este enfoque facilita seleccionar únicamente los elementos o atributos que resulten relevantes.
Existen dos tipos principales de direccionamiento:
- Absoluto: Siempre parte desde el nodo raíz del documento, especificando la ruta completa.
- Relativo: No requiere indicar el nodo raíz y permite trabajar con rutas basadas en el contexto actual.
Para ello, se utilizan las siguientes expresiones:
| Expresión | Definición |
|---|---|
| nodo | Elemento que tiene por nombre nodo |
| /nodo | Se encuentra en la raíz del documento |
| nodo1/nodo2 | Nodo2 es hijo directo nodo1 |
| nodo1//nodo2 | Nodo 2 es hijo de nodo1, pero puede haber otros intermedios |
| //nodo | Nodo puede estar en cualquier lugar debajo de nodo raiz |
| @atributo | Atributo que tiene por nombre atributo |
| * | Cualquier elemento |
| @* | Cualquier atributo |
| . | Nodo actual |
| .. | Nodo padre |
Ejemplos
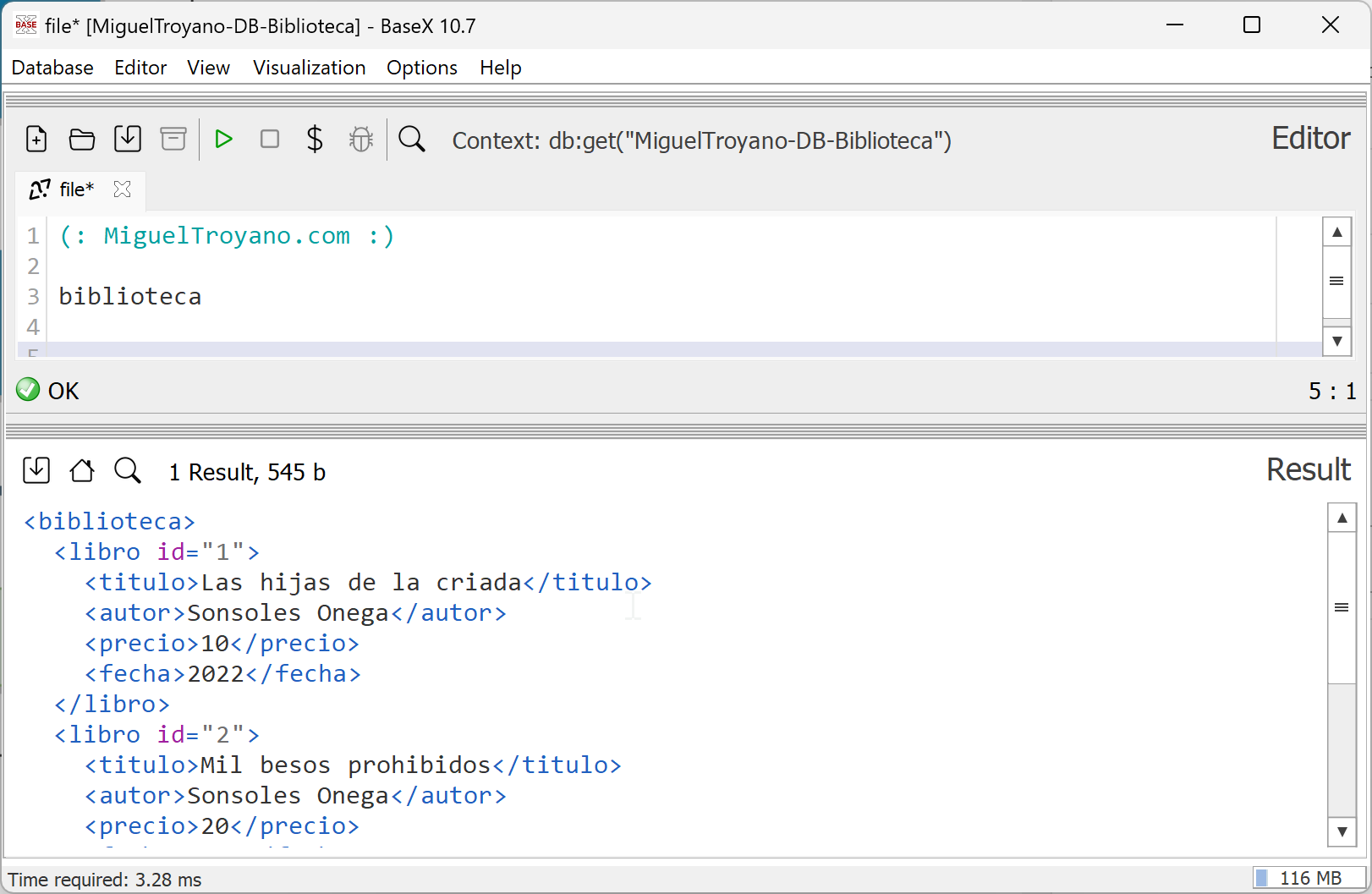
Para mostrar todo el contenido del archivo XML de la biblioteca, basta con escribir el nombre del nodo raíz en la consulta. Este método permite visualizar todos los datos almacenados en el documento. Por ejemplo:
biblioteca
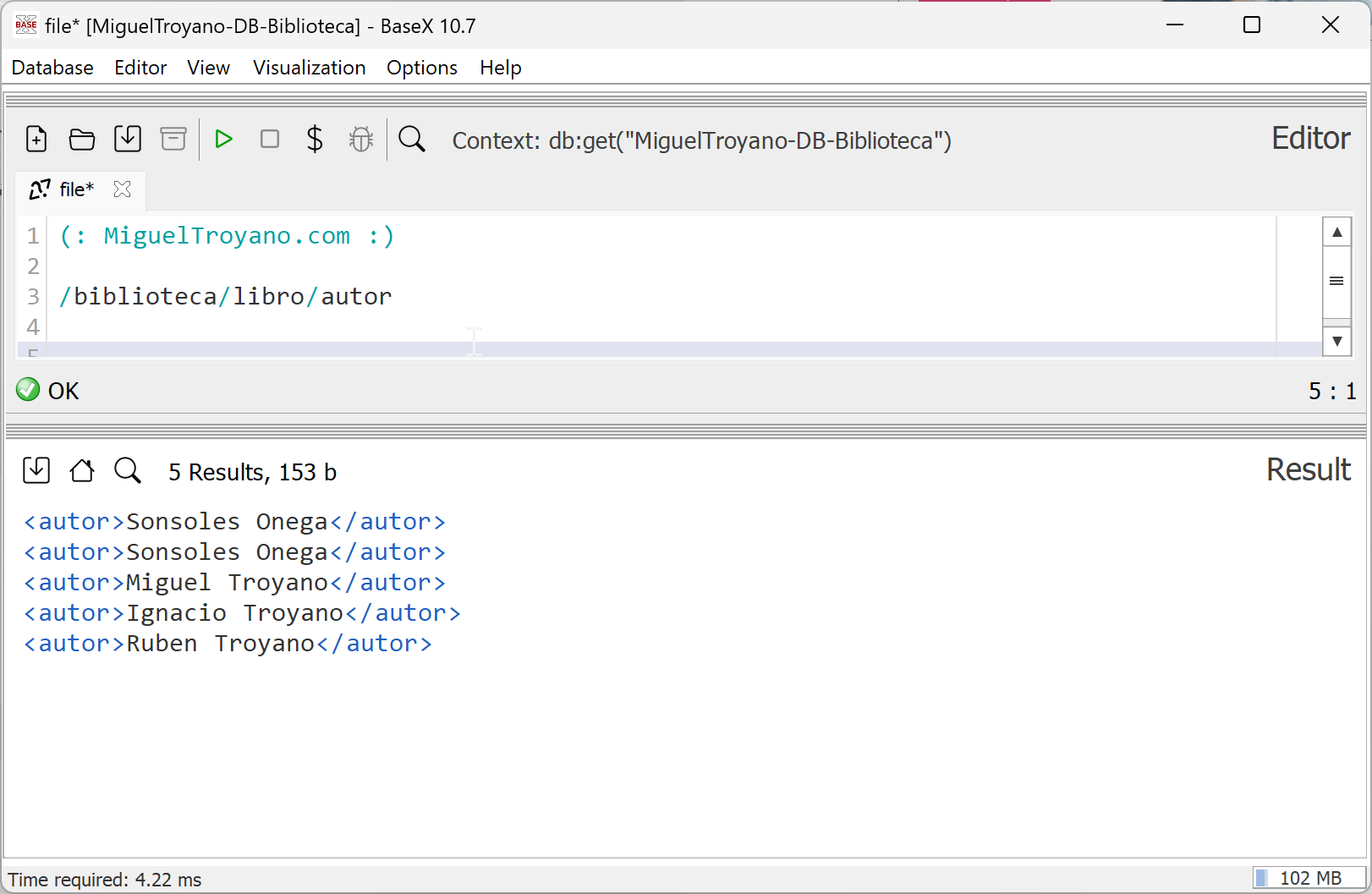
En este ejemplo de consultas en XPath, se utiliza una localización absoluta para acceder a los elementos específicos dentro del nodo raíz biblioteca. La consulta selecciona todos los libros y, dentro de ellos, sus respectivos autores:
/biblioteca/libro/autor
Se puede obtener exactamente el mismo resultado utilizando una localización relativa. Esto resulta útil cuando no es necesario partir explícitamente del nodo raíz. Por ejemplo:
//libro/autor //autor
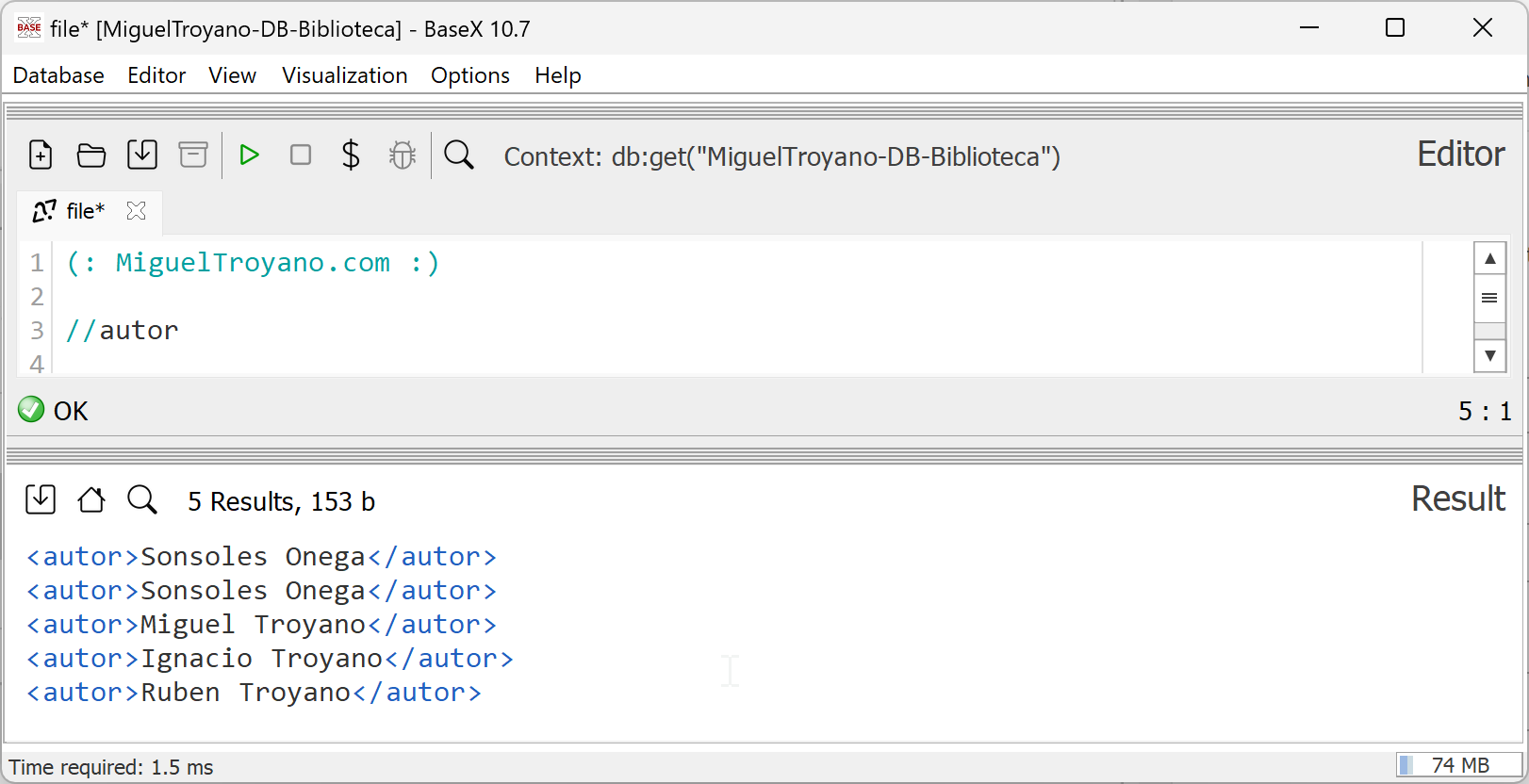
Ambas consultas buscan directamente todos los nodos autor, ya sea a partir de los nodos libro o desde cualquier parte del documento XML. Estas expresiones relativas simplifican las consultas al no requerir que se especifique la ruta completa desde el nodo raíz.
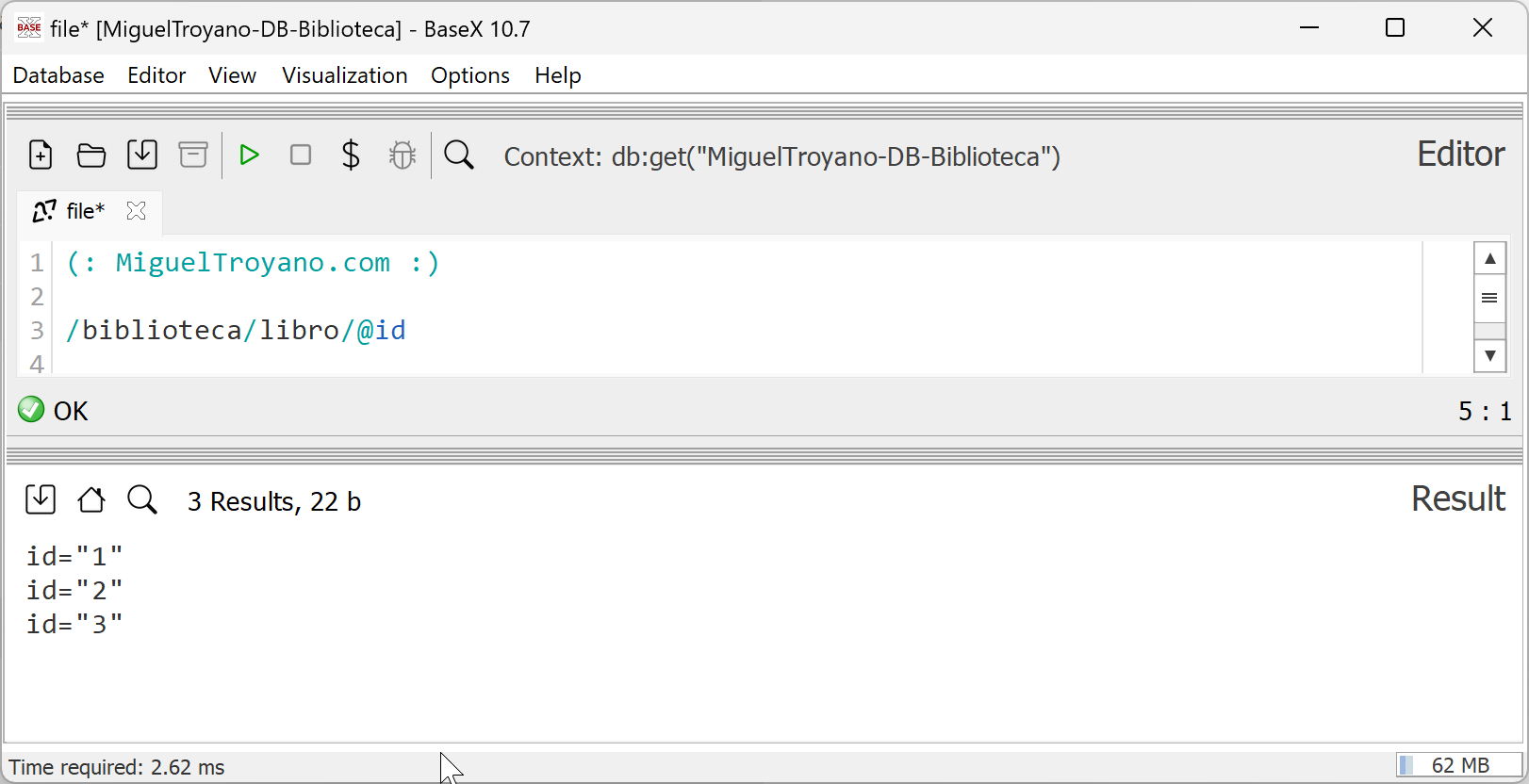
Si se desea obtener el ID, que es un atributo del nodo libro (diferente a los elementos hijos de este nodo), se utiliza la siguiente expresión:
/biblioteca/libro/@id
Esta consulta accede específicamente al atributo id de cada nodo libro dentro del nodo raíz biblioteca. Al ejecutarla en BaseX, se devolverán únicamente los valores de los atributos id, sin incluir el contenido de los elementos libro.
Otra opción es mostrar todos los atributos presentes en todos los nodos del documento XML. Para ello, se utiliza la siguiente expresión:
//@*
Esta consulta selecciona todos los atributos (@*) de cualquier nodo (//) dentro del documento. Al ejecutarla en BaseX, se devolverá una lista con todos los atributos y sus valores, independientemente del nodo al que pertenezcan.
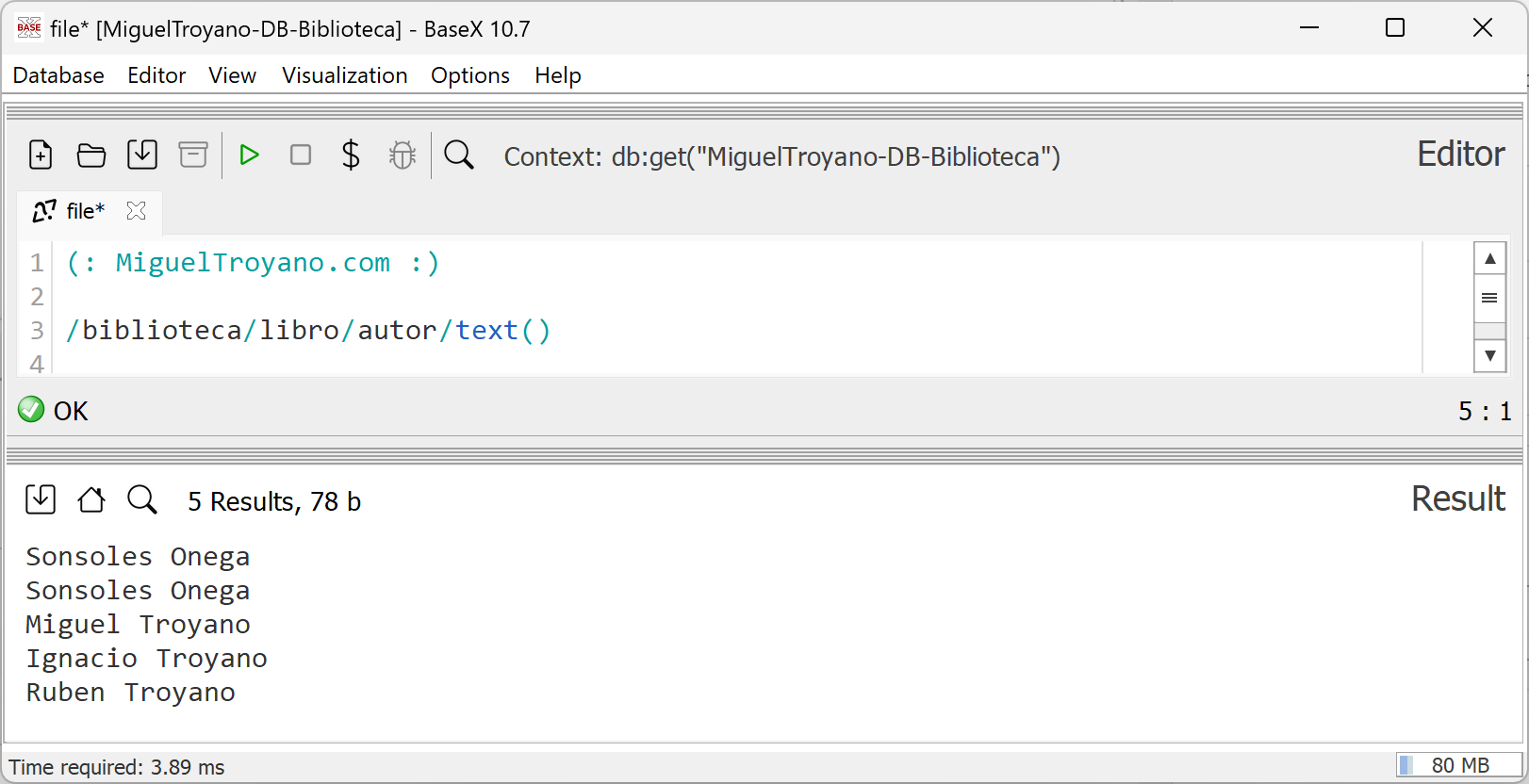
Otra opción muy útil es mostrar los resultados sin las etiquetas correspondientes, obteniendo únicamente el contenido de los nodos. Para esto, se utiliza la función text(), que extrae el valor del nodo sin incluir las etiquetas. Por ejemplo, si queremos mostrar únicamente los nombres de los autores, la consulta sería:
/biblioteca/libro/autor/text()
Al ejecutar esta consulta en BaseX, se obtendrán los valores de los nodos autor (es decir, los nombres de los autores) sin incluir las etiquetas <autor>. Esto es especialmente útil cuando solo se necesita el texto contenido en los nodos, sin la estructura XML.
Filtrar
También se puede filtrar el conjunto de nodos o la propia información utilizando condiciones. El filtro se debe especificar siempre entre corchetes y podemos utilizar los siguientes operadores y funciones (se muestran las más relevantes):
Operadores
| Operador | Descripción |
|---|---|
| and | Y |
| or | O |
| not | No es |
| = | Igual |
| != | Diferente |
| < | Menor que |
| > | Mayor que |
| <= | Menor o igual que |
| >= | Mayor o igual que |
| to | Rango |
| + | Suma |
| – | Resta |
| * | Multiplicación |
| div | División |
| mod | Resto de la división |
| | | Unión de resultados |
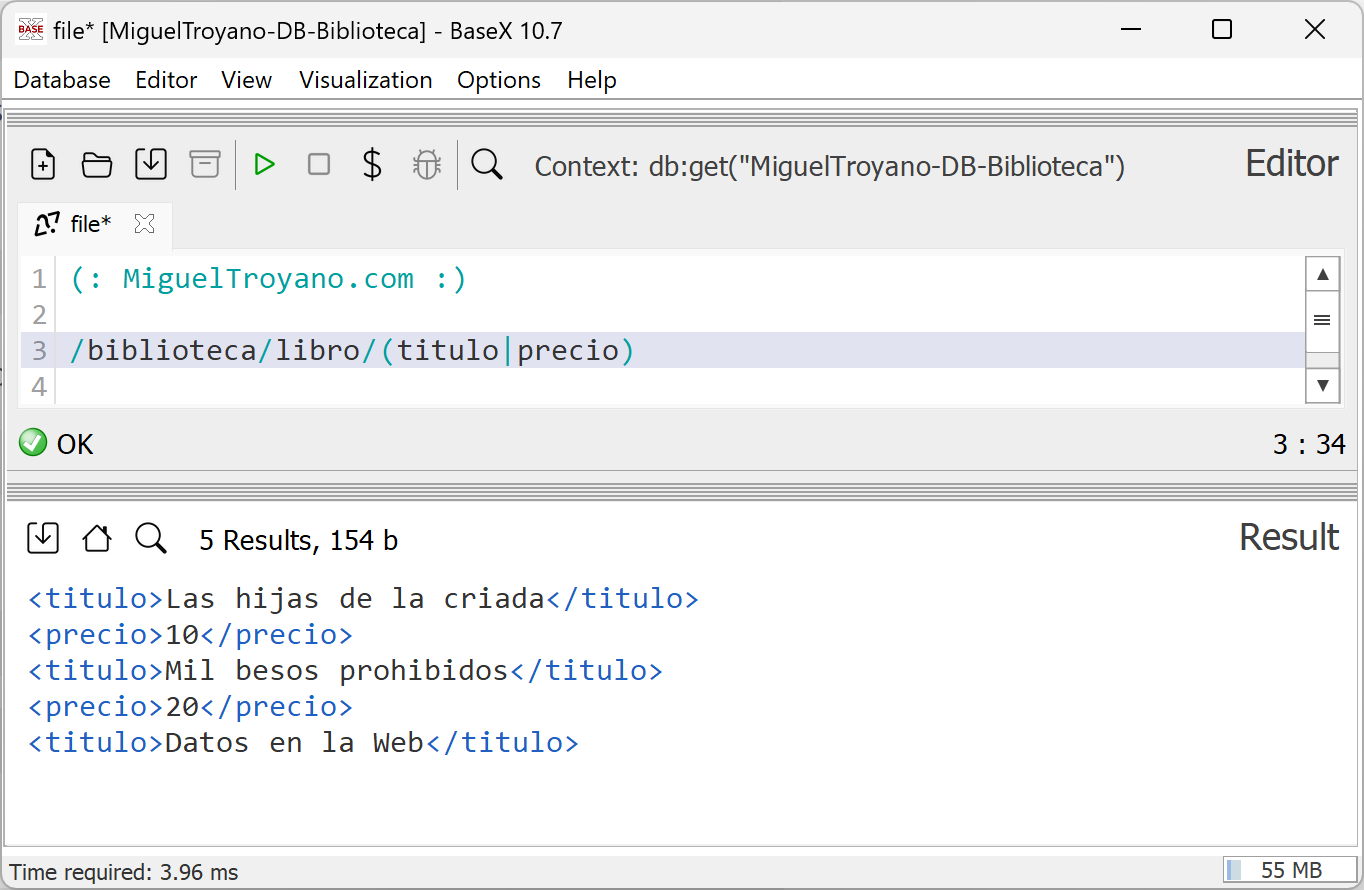
En este ejemplo vamos a mostrar tanto el título como el precio usando el operador de unión:
/biblioteca/libro/(titulo|precio)
Otro ejemplo utilizando operadores es mostrar los títulos de los libros cuyo año sea anterior a 2023. Para lograrlo, se utiliza la siguiente consulta:
/biblioteca/libro[fecha<2023]/titulo
En esta expresión, se aplica un filtro que selecciona únicamente los nodos libro cuyo valor en el nodo fecha sea menor a 2023. Luego, se accede al nodo titulo para obtener el nombre de esos libros. Al ejecutarla en BaseX, se mostrarán los títulos de los libros publicados antes de 2023.
Funciones de cadena
| Función | Descripción | Ejemplo |
|---|---|---|
| starts-with() | Cadena comienza | starts-with(‘XML’, ‘X’) = true |
| ends-with() | Cadena termina | ends-with(‘XML’, ‘X’) = false |
| substring() | Extracción de cadena | substring(‘MiguelTroyano’, 1, 6) = Miguel |
| contains() | La cadena contiene | contains(‘XML’, ‘ML’) = true |
| normalize-space() | Espacios normalizados | normalize-space(‘ Doc XML ‘) = ‘Doc XML’ |
| string-length() | Contar caracteres | string-length(‘MiguelTroyano’) = 13 |
| upper-case() | Convertir en minusculas | upper-case(‘xml’) = ‘XML’ |
| lower-case() | Convertir en mayúsculas | lower-case(‘XML’) = ‘xml’ |
| translate() | Sustitución de cadena | translate(‘Doc XML’, ‘XML’, ‘XPAth’) = ‘Doc XPAth’ |
Funciones numéricas
| Función | Descripción | Ejemplo |
|---|---|---|
| round() | Redondeo | round(3.88) = 3 |
| abs() | Valor absoluto | abs(-8) = 8 |
| floor() | Redondeo hacia abajo | floor(8.3) = 8 |
| ceiling | Redondeo hacia arriba | ceiling(8.3) = 9 |
Funciones de posición de elementos
| Función | Descripción |
|---|---|
| position() = n | Nodo que se encuentra en la posición ‘n’ |
| elemento[n] | Nodo en la posición ‘n’ de los que se llaman nodo |
| last() | El último nodo de un conjunto |
| last() – i | El último menos i nodos |
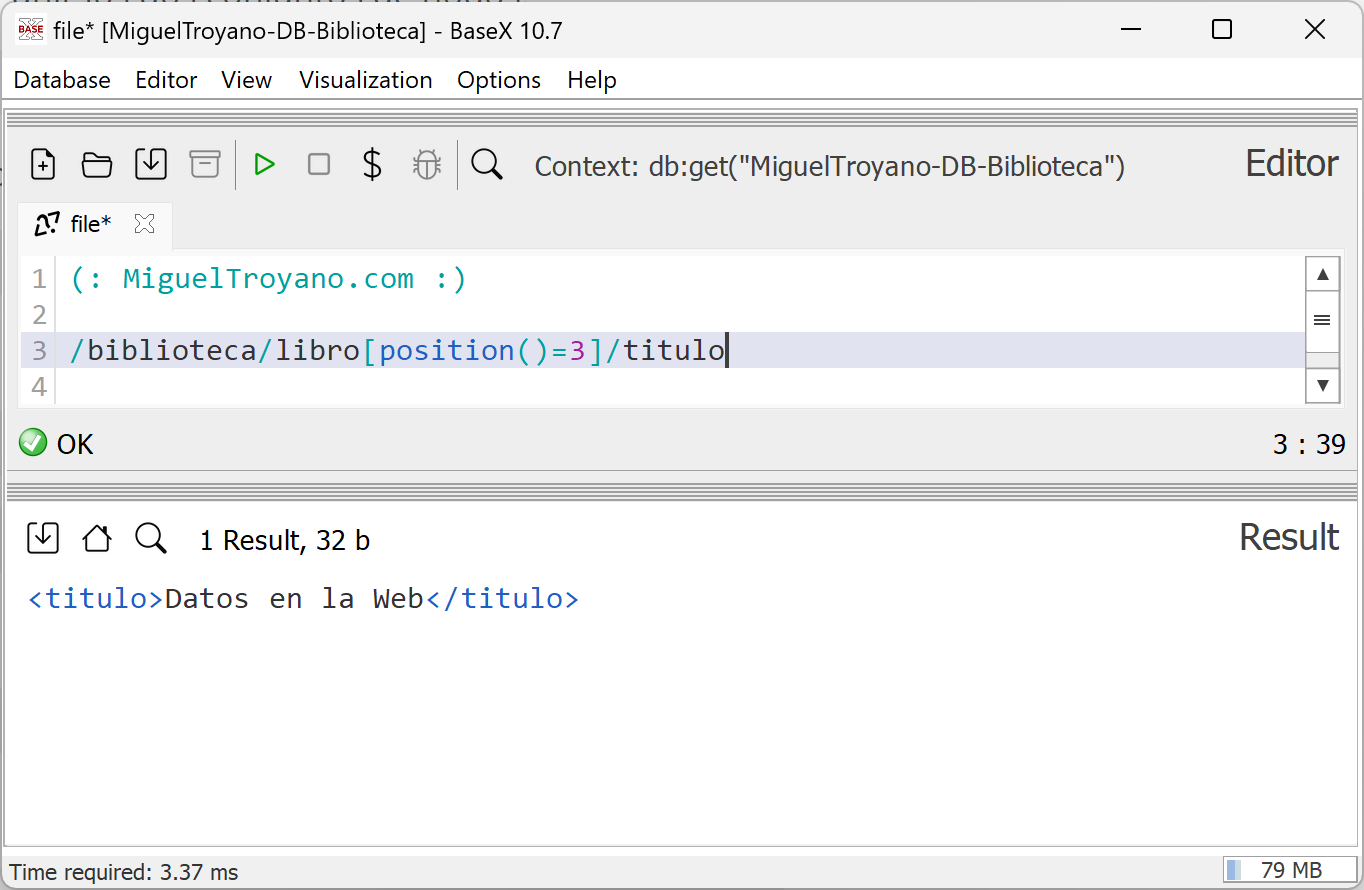
En este ejemplo, se utiliza una condición de posición para mostrar el título del libro que ocupa la tercera posición en el nodo biblioteca. La consulta es la siguiente:
/biblioteca/libro[position()=3]/titulo
Esta expresión selecciona el nodo libro que está en la tercera posición y, dentro de él, accede al nodo titulo. Al ejecutarla en BaseX, se devolverá únicamente el título del tercer libro presente en el documento XML.
No es necesario limitarse a una sola posición, también es posible seleccionar un rango de posiciones. En este ejemplo, se seleccionan los títulos de los libros que ocupan las posiciones 2 y 3 dentro del nodo biblioteca:
/biblioteca/libro[position()=2 to 3]/titulo
Esta consulta utiliza el rango 2 to 3 para filtrar los nodos libro comprendidos entre la segunda y la tercera posición. Luego, accede al nodo titulo para mostrar los títulos correspondientes. Al ejecutarla en BaseX, se devolverán los nombres de los libros ubicados en esas posiciones específicas.
Funciones de nodos
| Función | Descripción |
|---|---|
| comment() | Comentarios del nodo |
| empty() | Si el nodo está vacío o no |
| exists() | Si existe el nodo o no |
| name() | Nombre del nodo actual |
| node() | Nodos descendientes del actual |
| processing-instruction() | Instrucciones de procesamiento |
| root() | Elemento raíz |
| text() | Contenido textual del nodo |
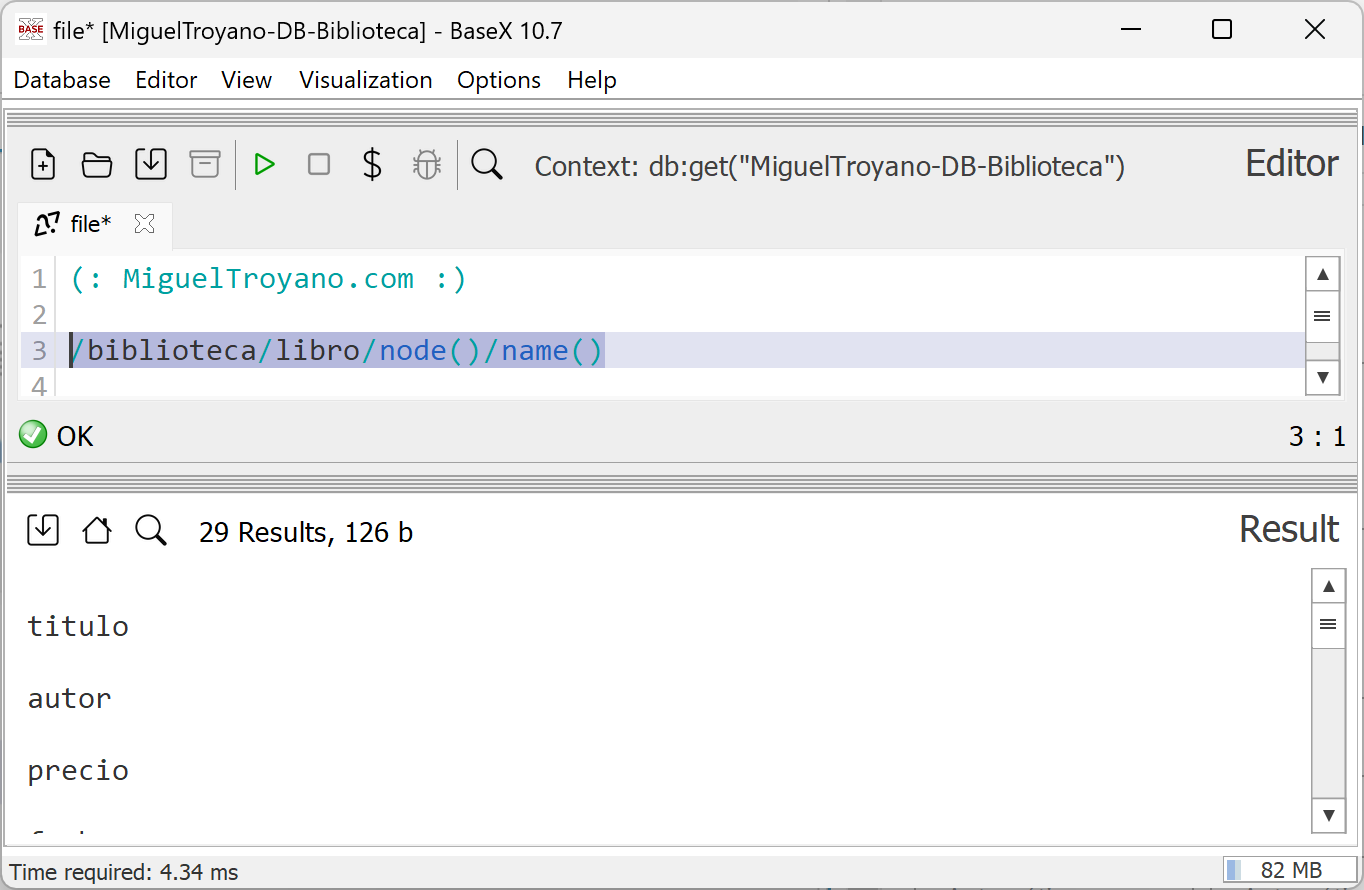
En este ejemplo, se muestra únicamente el nombre de los nodos descendientes del nodo actual. Para ello, se utiliza la siguiente consulta:
/biblioteca/libro/node()/name()
Esta consulta selecciona todos los nodos hijos del nodo libro utilizando node(), y luego aplica la función name() para obtener el nombre de cada nodo. Al ejecutarla en BaseX, se devolverá una lista con los nombres de los nodos descendientes dentro de cada libro, como titulo, autor, precio, entre otros.
Funciones de agregación
| Función | Descripción |
|---|---|
| avg() | Media |
| count() | Contar |
| max() | Valor máximo |
| min() | Valor mínimo |
| sum() | Suma |
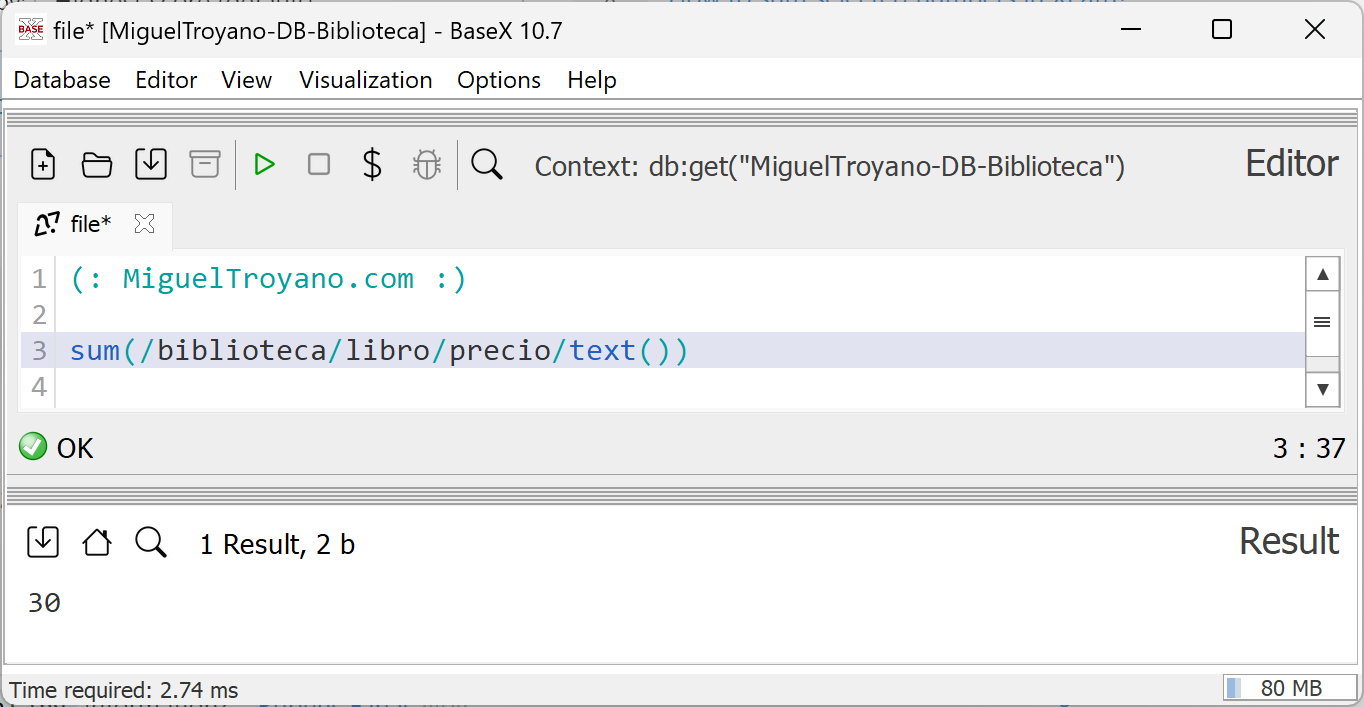
En este ejemplo, se realiza la suma de los precios de todos los libros dentro del nodo biblioteca. La consulta es la siguiente:
sum(/biblioteca/libro/precio/text())
La función sum() toma como entrada el conjunto de valores extraídos de los nodos precio mediante la expresión /biblioteca/libro/precio/text(). Al ejecutarla en BaseX, se calculará y devolverá la suma total de los precios de todos los libros presentes en el documento XML.
Consultas combinadas
Con todo lo anterior, es posible crear consultas mucho más complejas, como las consultas anidadas. Estas permiten resolver casos avanzados combinando varias condiciones dentro de una misma expresión. En el siguiente ejemplo, se busca primero el autor del libro titulado «Datos en la Web» y, posteriormente, se listan todos los libros escritos por ese autor:
/biblioteca/libro[autor=/biblioteca/libro[titulo="Datos en la Web"]/autor/text()]/titulo
La consulta funciona de la siguiente manera:
- La expresión interna
/biblioteca/libro[titulo="Datos en la Web"]/autor/text()obtiene el nombre del autor del libro con el título especificado. - Luego, en la expresión externa, se filtran todos los libros cuyos nodos
autorcoincidan con el resultado obtenido en el paso anterior. - Finalmente, se seleccionan los títulos de esos libros utilizando
/titulo.
Al ejecutar esta consulta en BaseX, se mostrará una lista con los títulos de todos los libros escritos por el autor de «Datos en la Web».